kubernetes基础知识
一、kubernetes介绍
Kubernetes本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器进行过管理。它的目的就是实现资源管理的自动化,主要提供了以下的主要功能:
- 自我修复:一旦某个容器崩溃,能够在1秒中左右迅速启动新的容器
- 弹性伸缩:可以根据需要,自动对集群中正在运行的容器数量进行调整
- 服务发现:服务可以通过自动发现的形式找到它所依赖的服务
- 负载均衡:如果一个服务启动了多个容器,能够自动实现请求的负载均衡
- 版本回退:如果发现新发布的程序版本有问题,可以立即回退到原来的版本
- 存储编排:可以根据容器自身的需求自动创建存储卷
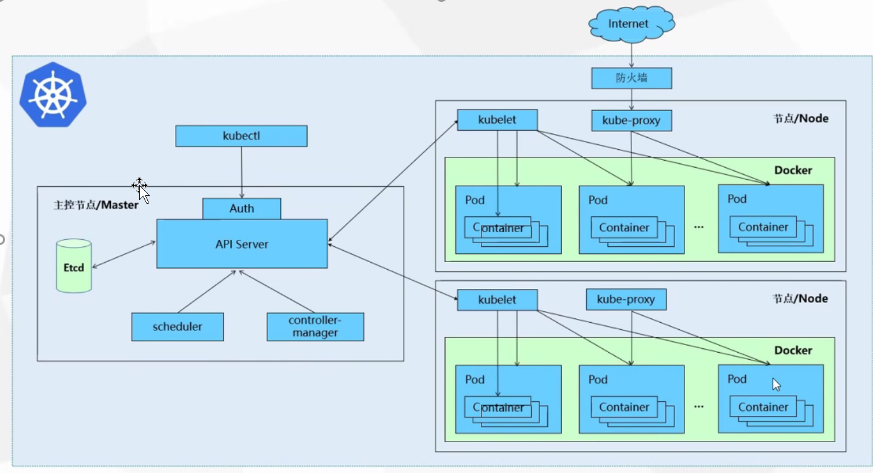
1.1、kubernetes组件
一个kubernetes集群主要由控制节点(master)、工作节点(node)构成,每个节点上都会安装不同的组件。
master:集群的控制平面,负责集群的决策
- ApiServer:资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制
- Scheduler:负责集群资源调度,按照预定的调度策略将Pod调度到相应的node节点上
- ControllerManager:负责维护集群的状态,比如程序部署安排、故障检测、自动扩展、滚蛋更新等
- Etcd:负责存储集群中各种资源对象的信息
node:集群的数据平面,负责为容器提供运行环境
- Kubelet:负责维护容器的生命周期,即通过控制docker,来创建、更新、销毁容器
- KuberProxy:负责提供集群内部的服务发现和负责均衡
- Docker:负责节点上容器的各种操作
下面以部署一个nginx服务来说明Kubernetes系统各个组件调用关系:
1、首先要明确,一旦k8s环境启动之后,master和node都会将自身信息存储到etcd数据库中
2、一个nginx服务的安装请求会被发送到master节点的apiServer组件
3、apiServer组件会调用schedule组件来决定到底应该把这个服务安装到哪个node节点上
4、apiServer调用controller-manager去调度Node节点去安装nginx服务
5、Kubelet接收到指令之后,会通知docker,然后由docker来启动一个nginx的pod,pod是kubernetes的最小操作单元,容器必须跑在pod中
6、一个nginx服务就运行了,如果需要访问nginx,就需要通过kube-proxy来对pod产生访问的代理。这样,外界用户就可以访问集群中的nginx服务
1.2、Kubernetes概念
Master:集群控制节点,每个集群需要至少一个master节点来负责集群的管控
Node:工作负载节点,由master分配容器到这些node工作节点上,然后node节点上的docker负责容器的运行
Pod:kubernetes的最小控制单元,容器都是运行在pod中的,一个pod可以有1个或者多个容器
Controller:控制器,通过它来实现对pod的管理,比如启动pod、停止pod、伸缩pod的数量等等
Service:pod对外服务的统一入口,下面可以维护者同一类的多个pod
Label:标签,用于对pod进行分类,同一类pod会拥有相同的标签
NameSpace:命令空间,用来隔离pod的运行环境
二、 集群环境搭建
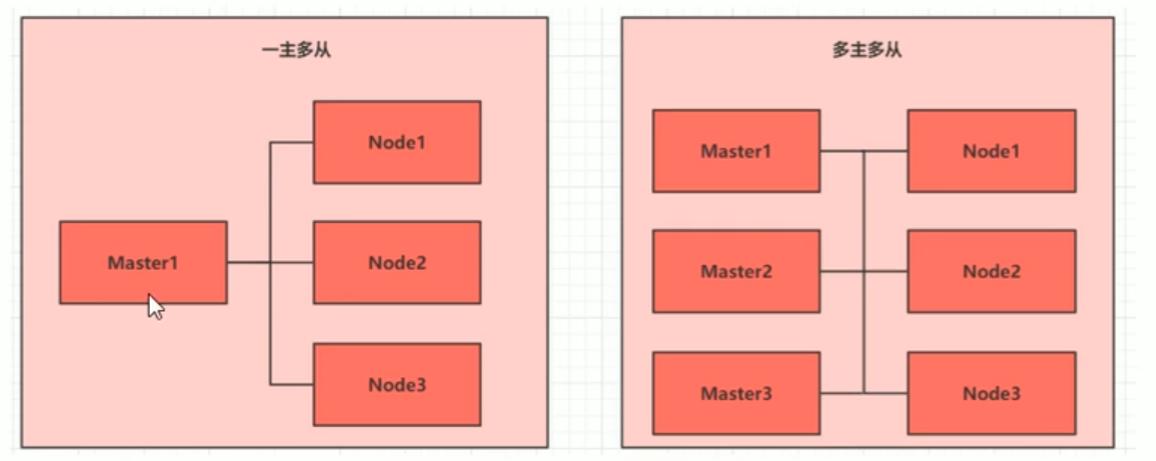
2.1、集群类型
Kubernertes集群大体分为两类:一主多从和多主多从
- 一主多从:一台master节点和多台node节点,搭建简单,但是有单机故障风险,适合用于测试环境
- 多主多从:多台master节点和多台node节点,搭建麻烦,安全性高,适合用于生产环境
2.2、安装方式
Kubernetes有多种部署方式,目前主流的方式有kubeadm、minikube、二进制包
- minikube:一个用于快速搭建单节点kubernetes的工具
- kubeadm:应该用于快速搭建kubernetes集群的工具
- 二进制包:从官网下载每个组件的二进制包,依次去安装
| 主机名 | IP | 配置 | 系统发行版 |
|---|---|---|---|
| master | 192.168.80.10 | 4C2G | CentOS Linux release 7.8 |
| node1 | 192.168.80.11 | 4C2G | CentOS Linux release 7.8 |
| node2 | 192.168.80.12 | 4C2G | CentOS Linux release 7.8 |
2.3.1、搭建三台虚拟机
搭建k8s,系统发行版需要至少centos7.5,需要预留/var目录下预留≥5G的足够的空间
1 这里采用了阿里云7.8的CentOS-7-x86_64-Minimal-2003.iso
链接地址:https://mirrors.aliyun.com/centos-vault/7.8.2003/isos/x86_64/?spm=a2c6h.25603864.0.0.454a60bdb8NRXT
2 如果是挂载新iso,利用F2或者F12进BIOS,改光盘驱动安装iso
3、更改centos的yum源为阿里云
cd /etc/yum.repos.d/
mv CentOS-Base.repo CentOS-Base.repo.backup
curl https://mirrors.aliyun.com/repo/Centos-7.repo
vi CentOS-Base.repo 将curl内容复制进去
4、yum install -y wgt 验证成功
2.3.2、主机名解析
主机名成解析 编辑三台服务器的/etc/hosts文件,添加下面内容
# 192.168.80.10 master
# 192.168.80.11 node1
# 192.168.80.12 node22.3.3、时间同步
kubernetes要求集群中的节点时间必须精确一致,这里直接使用chronyd服务从网络同步时间
#启动chronyd服务
[root@master ~]# systemctl start chronyd
#设置chronyd服务开机自启
[root@master ~]# systemctl enable chronyd
#chronyd服务启动稍等几秒钟,就可以使用date命令验证时间了
[root@master ~]# date
2025年 08月 04日 星期一 17:08:57 CST
2.3.4、禁用iptables和firewalld服务
kubernetes和docker在运动中会产生大量的iptables规则,为了不让系统规则跟它们混淆,直接关闭系统的规则
#关闭firewalld服务
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
#关闭iptables服务
[root@master ~]# systemctl stop iptables
Failed to stop iptables.service: Unit iptables.service not loaded.
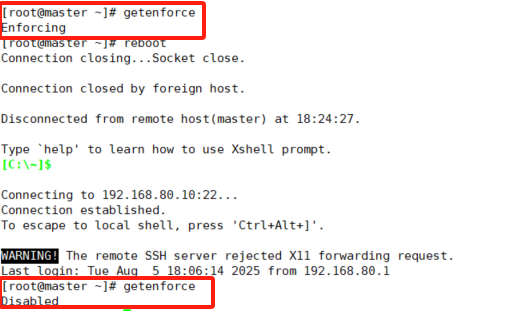
2.3.5、禁用selinux
selinux是linux系统下的一个安全服务,如果不关闭它,在安装集群中会产生各种各样的奇葩问题
#编辑/etc/selinux/config文件,修改SELINUX的值为disabled
#注意修改完毕之后需要重启linux服务
SELINUX=disabled
#通过getenforce来命令检查是否生效
2.3.6、禁用swap分区
swap分区指的是虚拟内存分区,它的作用是在物理内存使用完之后,将磁盘空间虚拟成内存来使用
启用swap设备会对系统的性能产生非常负面的影响,因此kubernetes要求每个节点都要禁用swap设备,
但是如果因为某些原因确实不能关闭swap,就需要在集群安装过程当中通过明确的参数进行配置说明。
#编辑分区配置文件/etc/fstab,注释掉swap分区一行
#注意修改完毕之后需要重启linux服务
[root@master ~]# vim /etc/fstab
/dev/mapper/centos00-root / xfs defaults 0 0
UUID=77663676-1afb-461c-997d-26c7b5e1f096 /boot xfs defaults 0 0
#/dev/mapper/centos00-swap swap swap defaults 0 0检查是否swap为禁用状态

2.3.7、修改linux的内核参数
#修改linux的内核参数,添加网桥过滤和地址转发功能
#编辑/etc/sysctl.d/kubernetes.conf文件,添加如下配置:
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
#重新加载配置
[root@master ~]# sysctl -p
#加载网桥过滤模块
[root@master ~]# modprobe br_netfilter
#查看网桥过滤模块是否加载成功
[root@master ~]# lsmod | grep br_netfilter
br_netfilter 22256 0
bridge 151336 1 br_netfilter2.3.8、配置ipvs功能
在kubernetes中service有两种代理模型,一种是基于iptables的,一种是基于ipvs的
两者比较的话,ipvs的性能明显要高一些,但是如果需要使用它,需要手动载入ipvs模块
#1 安装ipset和ipvsadm
[root@master yum.repos.d]# yum install ipset ipvsadmin -y
#2 添加需要加载的模块写入脚本
[root@master yum.repos.d]#cat <<EOF > /etc/sysconfig/modules/ipvs.modules
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
#3 为脚本文件添加执行权限
[root@master modules]# chmod +x /etc/sysconfig/modules/ipvs.modules
#4 执行脚本文件
[root@master modules]# /bin/bash /etc/sysconfig/modules/ipvs.modules
#5 查看对应的模块是否加载成功
[root@master modules]# lsmod | grep -e ip_vs -e nf_conntrack_ipv4
nf_conntrack_ipv4 15053 0
nf_defrag_ipv4 12729 1 nf_conntrack_ipv4
ip_vs_sh 12688 0
ip_vs_wrr 12697 0
ip_vs_rr 12600 0
ip_vs 145497 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack 139264 2 ip_vs,nf_conntrack_ipv4
libcrc32c 12644 3 xfs,ip_vs,nf_conntrack
执行完以上所有步骤,需要重新启动linux系统
reboot
2.4、安装docker和cri-dockerd
三台都需要安装
2.4.1、安装docker
详见http://www.kervin24.top/?p=229 docker基础教程
1、安装依赖包
yum install -y yum-utils device-mapper-persistent-data lvm2
-------------------------------------
yum-utils:提供了yum-config-manager工具。
devicemapper:是Linux内核中支持逻辑卷管理的通用设备映射机制,它为实现用于存储资源管理的块设备驱动提供了一个高度模块化的内核架构。
device mapper:存储驱动程序需要device-mapper-persistent-data和lvm2。
2、设置阿里云镜像源
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
3、安装Docker-CE并设置为开机自动启动
yum install -y docker-ce docker-ce-cli containerd.io
-----------------------------------
报错解决:
这个报错是container-selinux版本低或者是没安装的原因
yum 安装container-selinux 一般的yum源又找不到这个包
需要安装epel源 才能yum安装container-selinux
然后在安装docker-ce就可以了。
########################
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
yum install epel-release
yum makecache
yum install container-selinux
####################
systemctl start docker.service
systemctl enable docker.service
--------------------------------------------------
安装好的Docker系统有两个程序,Docker服务端和Docker客户端。其中Docker服务端是一个服务进程,负责管理所有容器。
Docker客户端则扮演着Docker服务端的远程控制器,可以用来控制Docker的服务端进程。大部分情况下Docker服务端和客户端运行在一台机器上。
4、配置镜像加速配置
修改配置文件/etc/docker/daemon.json(没有时新建该文件)。
-------------------
{
"registry-mirrors": [
"https://docker.xuanyuan.me" ,
"https://docker.m.daocloud.io",
"https://docker.imgdb.de",
"https://docker-0.unsee.tech",
"https://docker.hlmirror.com",
"https://docker.1ms.run",
"https://func.ink",
"https://lispy.org",
"https://docker.xiaogenban1993.com"
]
}
---------------------
systemctl daemon-reload ###然后重启Docker Daemon。
systemctl restart docker
2.4.2、安装cri-dockerd
以下参考https://bbs.huaweicloud.com/blogs/433368
kubernetes1.24版本开始不再支持docker 因此,还需要安装cri-dockerd来用于为Docker提供一个能够支持K8S容器运行时标准的工具
#安装cri-dockerd
# 通过 wget 命令获取 cri-dockerd软件
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.12/cri-dockerd-0.3.12-3.el7.x86_64.rpm
# 通过 rpm 命令执行安装包
rpm -ivh cri-dockerd-0.3.12-3.el7.x86_64.rpm
#安装完成后修改配置文件(/usr/lib/systemd/system/cri-docker.service),
在 “ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd://”
这一行增加 “--pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9”。
#配置文件修改后,重新加载配置并开启 cri-dockerd 服务。
# 加载配置并开启服务
systemctl daemon-reload
systemctl enable cri-docker && systemctl start cri-docker
2.5、安装kuberbetes组件
三台都需要安装
1、 #编辑/etc/yum.repos.d/kubernetes.repo,添加以下配置
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
2、#安装kubeadm、kubelet和kubect1 (目前最新版本1.28-0)
yum install -y kubelet-1.28.0 kubeadm-1.28.0 kubectl-1.28.0
#配置kubernet的cgroup
#编辑/etc/sysconfig/kubelet,添加下面的配置
KUBELET_CGROUP_ARGS="--cgroup-driver=systemd"
KUBE_PROXY_MODE="ipvs"
3、# 设置 kubelet 自启动
systemctl enable kubelet
#在安装kubernetes集群之前,查看所需镜像可以通过下面命令查看
[root@master yum.repos.d]# kubeadm config images list
I0807 22:34:11.171481 4387 version.go:256] remote version is much newer: v1.33.3; falling back to: stable-1.28
registry.k8s.io/kube-apiserver:v1.28.15
registry.k8s.io/kube-controller-manager:v1.28.15
registry.k8s.io/kube-scheduler:v1.28.15
registry.k8s.io/kube-proxy:v1.28.15
registry.k8s.io/pause:3.9
registry.k8s.io/etcd:3.5.9-0
registry.k8s.io/coredns/coredns:v1.10.1
2.6、集群初始化
2.6.1、Master节点加入K8S集群
下面的操作只需要在master节点上执行
kubeadm init \
--apiserver-advertise-address=192.168.80.10 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.28.0 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--cri-socket=unix:///var/run/cri-dockerd.sock \
--ignore-preflight-errors=all
相关参数解释:
apiserver-advertise-address:集群广播地址,用 master 节点的内网 IP。
image-repository:由于默认拉取镜像地址 k8s.gcr.io 国内无法访问,这里指定阿里云镜像仓库地址。
kubernetes-version: K8s 版本,与上面安装的软件版本一致。
service-cidr:集群 Service 网段。
pod-network-cidr:集群 Pod 网段。
cri-socket:指定 cri-socket 接口,我们这里使用 unix:///var/run/cri-dockerd.sock。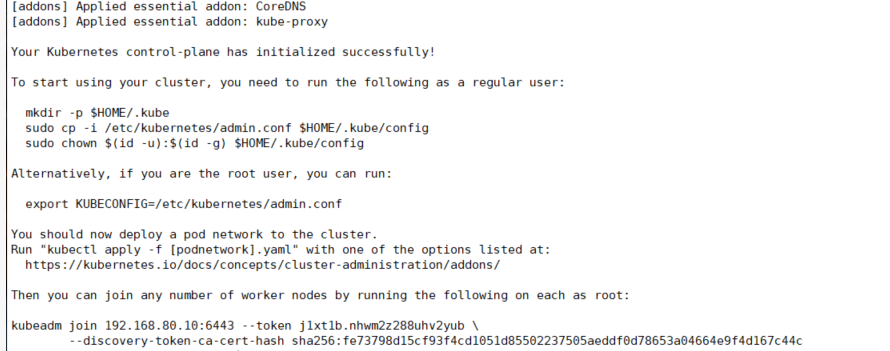
执行命令后耐心等待,直到安装完成,会出现以上内容。
其中,在以上返回结果中有 3 条命令需要立即执行,这是用来设置 kubectl 工具的管理员权限,执行之后就可以在 Master 节点上通过终端窗口使用 kubectl 命令。
# 在 Master 节点上执行以下命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
2.6.2、Node节点加入K8S集群
K8s 初始化之后,就可以在其他 2 个工作节点上执行 “kubeadm join” 命令,
因为我们使用了 cri-dockerd ,需要在命令加上 “–cri-socket=unix:///var/run/cri-dockerd.sock” 参数。
在master节点上,可重新生成并获取token和sha256
[root@master /]# kubeadm token create --print-join-command
kubeadm join 192.168.80.10:6443 --token uobpxl.g3wk6xz24ubdw0hi --discovery-token-ca-cert-hash sha256:fe73798d15cf93f4cd1051d85502237505aeddf0d78653a04664e9f4d167c44c
# 在两个工作节点上执行
kubeadm join 192.168.80.10:6443 --token uobpxl.g3wk6xz24ubdw0hi \
--discovery-token-ca-cert-hash sha256:fe73798d15cf93f4cd1051d85502237505aeddf0d78653a04664e9f4d167c44c \
--cri-socket=unix:///var/run/cri-dockerd.sock
#在master节点上执行get nodes查看集群节点状态
[root@master /]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master NotReady control-plane 23m v1.28.2
node1 NotReady <none> 26s v1.28.2
node2 NotReady <none> 7s v1.28.2
注意到所有节点的状态都是 “NotReady”,这是由于集群还缺少网络插件,集群的内部网络还没有正常运作。
2.7、安装网络插件calico
kubernetes支持多种网络插件,比如flannel、calico、canal等等,本次选择calico
# 下载 Calico 插件部署文件
wget https://docs.projectcalico.org/manifests/calico.yaml
通过vi编辑器修改 “calico.yaml”的4601和4602行
文件中的 “CALICO_IPV4POOL_CIDR” 参数,
需要与前面 “kubeadm init” 命令中的 “–pod-network-cidr” 参数一样(10.244.0.0/16)
[root@master opt]# kubectl apply -f calico.yaml
#这里要稍微等一会,calico生效很慢,可以重启服务器尝试 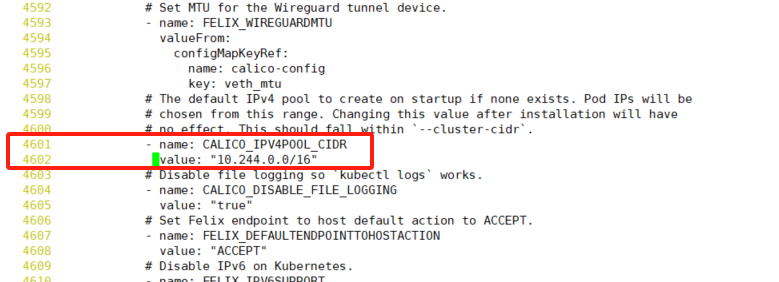
三、资源管理
3.1、资源管理介绍
在kubernetes中,所有的内容都抽象为资源,用户需要通过操作资源来管理kubernetes
- kubernetes的本质是一个集群系统,用户可以在集群中部署各种服务,所谓的部署服务,其实就是在kubernetes集群中运行一个个容器,并将指定的程序跑在容器中。
- kubernetes的最小管理单元是pod而不是容器,所以只能将容器放在Pod中,而kubernetes一般也不会直接管理Pod,而是通过Pod控制器来管理Pod的。
- Pod可以提供服务之后,就要考虑如何访问Pod中的服务,Kubernetes提供了Service资源实现这个功能
- 当然,如果Pod中程序的数据需要持久化,kubernetes还提供了各种存储系统
3.2、资源管理方式
- 命令式对象管理:直接使用命令去操作Kubernetes资源
kubectl run nginx-pod --image=nginx:1.17.1 --port=80
- 命令式对象配置:通过命令配置和配置文件去操作kubernetes资源
kubetcl create/patch -f nginx-pod.yaml
- 声明式对象配置:通过apply命令和配置文件去操作kubernetes资源
kubectl apply -f nginx-pod.yaml
| 类型 | 操作对象 | 适用环境 | 优点 | 缺点 |
|---|---|---|---|---|
| 命令式对象管理 | 对象 | 测试 | 简单 | 只能操作活动对象,无法审计、跟踪 |
| 命令式对象配置 | 文件 | 开发 | 可以审计、跟踪 | 项目大时,配置文件多,操作麻烦 |
| 声明式对象配置 | 目录 | 开发 | 支持目录操作 | 意外情况下难以调试 |
3.2.1、命令式对象管理
kubectl命令
kubect是kubernetes集群的命令行工具,通过它能够对集群本身进行管理,并能够在集群上进行容器化应用的安装部署,kubectl命令的语法如下:
kubectl [command] [type] [name] [flags]
- command:指定要对资源执行的操作,例如:create、get、delete
- type:指定资源类型,比如:deployment、pod、service
- name:指定资源的名称,名称大小写敏感
- flags:指定额外的可选参数
#查看所有
pod kubectl get pod
#查看某个
pod kubectl get pod pod_name
#查看某个pod,以yaml格式展示结构
kubectl get pod pod_name -o yaml资源类型
kubernetes中所有的内容都抽象为资源,可以通过--help查看详细的命令
kubectl --help
下面以一个namespace的创建和删除简单演示下命令的使用:
#创建一个namespace
[root@master01 ~]# kubectl create namespace dev
namespace/dev created
#获取namespace
[root@master01 ~]# kubectl get ns
NAME STATUS AGE
default Active 3y20d
dev Active 49s
kube-node-lease Active 3y20d
kube-public Active 3y20d
kube-system Active 3y20d
kubernetes-dashboard Active 3y20d
#在此namespace下创建并运行一个nginx的pod
[root@master01 ~]# kubectl run nginx-pod --image=nginx:latest -n dev
pod/nginx-pod created
#查看新创建的pod
[root@master01 ~]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
nginx-pod 1/1 Running 0 23s
[root@master01 ~]# kubectl describe pod -n dev
#删除指定的pod
[root@master01 ~]# kubectl delete pod nginx-pod -n dev
pod "nginx-pod" deleted
#删除指定的namespace
[root@master01 ~]# kubectl delete ns dev
namespace "dev" deleted
3.2.2、命令式对象配置
命令式对象配置就是使用命令配合配置文件一起来操作kubernetes资源
1)创建一个nginxpod.yaml,内容如下:
apiVersion: v1
kind: Namespace
metadata:
name: dev
---
apiVersion: v1
kind: Pod
metadata:
name: nginxpod
namespace: dev
spec:
containers:
- name: nginx-containers
image: nginx:1.17.1
2)执行create命令,创建资源:
[root@master01 ~]# kubectl create -f nginxpod.yaml
namespace/dev created
pod/nginxpod created
此时发现创建了两个资源对象,分别是namespace和pod
3)执行get命令,查看资源
[root@master01 ~]# kubectl get -f nginxpod.yaml
NAME STATUS AGE
namespace/dev Active 2m31s
NAME READY STATUS RESTARTS AGE
pod/nginxpod 0/1 ContainerCreating 0 2m30s
4)执行delete命令,删除资源对象
[root@master01 ~]# kubectl delete -f nginxpod.yaml
namespace "dev" deleted
pod "nginxpod" deleted此时发现两个资源对象被删除了
[root@master01 ~]# kubectl delete -f nginxpod.yaml
namespace "dev" deleted
pod "nginxpod" deleted
总结:命令式对象配置的方式操作资源,可以简单的认为:命令+yaml配置文件(里面是命令需要的各种参数)
3.2.3、声明式对象配置
声明式对象配置 跟命令式对象配置很相似,但是它只有一个命令apply
#首先执行一次kubectl apply -f yaml文件,发现创建了资源
[root@master01 ~]# kubectl apply -f nginxpod.yaml
namespace/dev created
pod/nginxpod created
#再次执行一次kubectl apply -f yaml文件,发现说资源没有变动
[root@master01 ~]# kubectl apply -f nginxpod.yaml
namespace/dev unchanged
pod/nginxpod unchanged
总结:
其实声明式对象配置就是使用apply描述一个资源最终的状态(在yaml中定义状态)
使用apply操作资源:
如果资源不存在,就创建,相当于kubectl create
如果资源已存在,就更新,相当于kubectl patch
4.1、Namespace
Namespace是kubernetes系统中非常重要资源,它的主要作用是用来实现多套环境的资源隔离或者多租户的资源隔离
默认情况下,kuberne集群中的所有的Pod都是可以相互访问的,但是在实际中,可能不想让两个Pod之间进行互相的访问,那此时就可以将两个Pod划分到不同的namespace下。kubernetes通过将集群内部的资源分配到不同的namespace中,可以形成逻辑上的组,以方便不同的组的资源进行隔离使用和管理。
可以通过kubernetes的授权机制,将不同的namespace交给不同租户进行管理,这样就实现了多租户的资源隔离。此时还能结合kubernetes的资源配额机制,限定不同租户能占用的资源,例如CPU使用量、内存的使用量等等,来实现租户可用资源的管理。
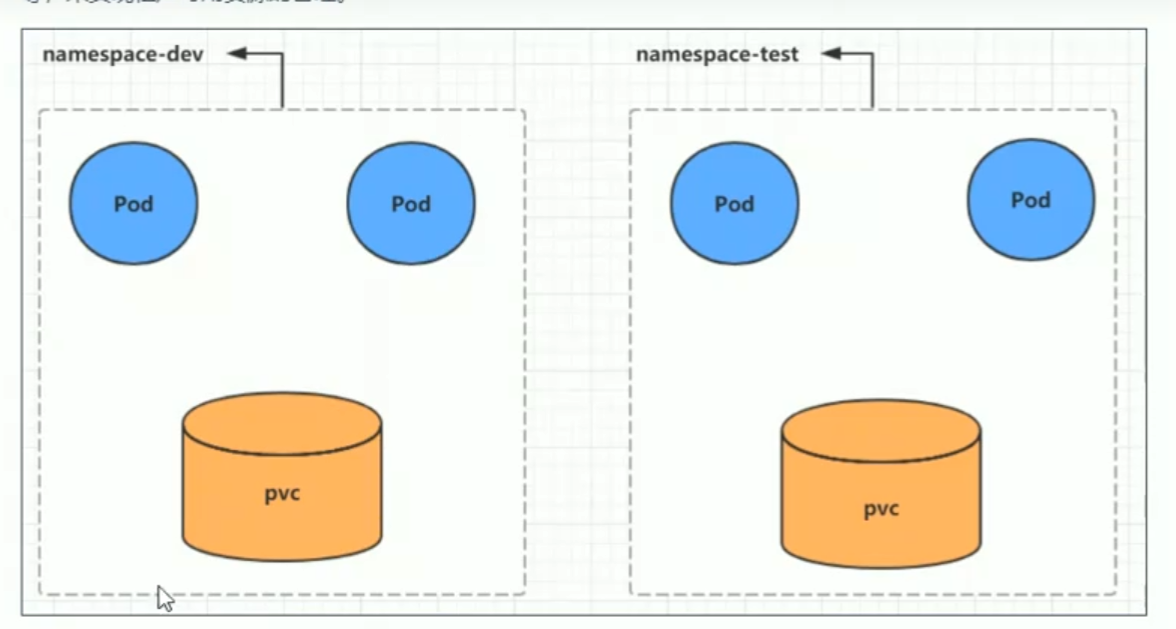
kubernetes在集群启动之后,会默认创建几个namespace
查询
[root@master01 ~]# kubectl get ns default
NAME STATUS AGE
default Active 3y21d
#查看ns详情 命令:kubectl describe ns ns名称
[root@master01 ~]# kubectl describe ns default
Name: default
Labels: <none>
Annotations: <none>
Status: Active #Active命令空间正在使用中, Terminating正在删除命令空间
No resource quota. #resource quota针对namespace做的资源限制
No LimitRange resource. #limitrange针对namespace中的每个组件做的资源限制创建
#创建namespace
[root@master01 ~]# kubectl create ns abc
namespace/abc created删除
#删除namespace
[root@master01 ~]# kubectl delete ns abc
namespace "abc" deleted配置方式
首先准备一个yaml文件:ns-dev.yaml
apiVersion: v1
kind: Namespace
metadata:
name: abc然后就可以执行对应的创建和删除命令了:
创建:kubectl create -f ns-dev.yaml
删除:kubectl delete -f ns-dev.yaml
4.2、Pod
Pod是kubernetes集群进行管理的最小单元,程序要运行必须部署在容器中,而容器必须存在于Pod中。
Pod可以认为是容器的封装,一个Pod中可以存在一个或者多个容器
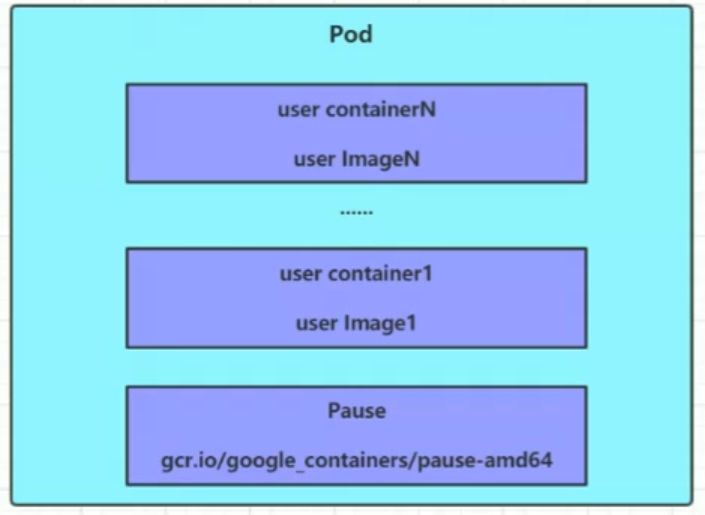
kubernetes在集群启动之后,集群中的各个组件也都是以Pod方式运行的。可以通过下面命令查看:
[root@master01 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-6954c77b9b-kf66w 1/1 Running 6 3y21d
kube-flannel-ds-6bc26 1/1 Running 6 3y21d
kube-flannel-ds-gvxt5 1/1 Running 8 3y21d创建并运行
kubernetes没有提供单独运行pod的命令,都是通过Pod控制器来实现的
#命令格式:kubectl run (pod控制器名称) [参数]
#--image 指定pod的镜像
#--port 指定端口
#--namespace 指定namespace
[root@master01 ~]# kubectl run nginx --image=nginx:1.17.1 --port 80 --namespace dev
pod/nginx created查看pod信息
# -o wide 查看更多信息
[root@master01 ~]# kubectl get pod -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 2m22s 10.244.0.19 192.168.80.11 <none> <none>
nginxpod 1/1 Running 1 13h 10.244.1.26 192.168.80.12 <none> <none>
[root@master01 ~]# kubectl describe pod nginx -n dev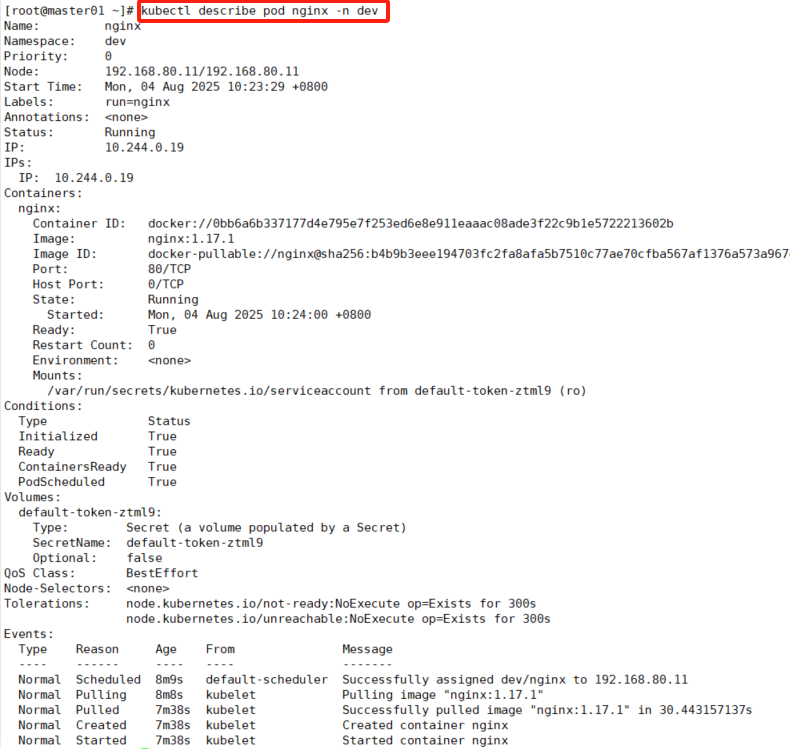
删除Pod
kubectl run的方式是通过控制器deployment来创建pod
只有kubectl delete deployment的方式才能删除pod
[root@master ~]# kubectl get pod -n default
NAME READY STATUS RESTARTS AGE
nginx-596ff96db7-vwgq4 1/1 Running 0 8m9s
#尝试delete删除pod
[root@master ~]# kubectl delete pod nginx-596ff96db7-vwgq4 -n default
pod "nginx-596ff96db7-vwgq4" deleted
#发现删除完了之后,会又新建一个pod
[root@master ~]# kubectl get pod -n default
NAME READY STATUS RESTARTS AGE
nginx-596ff96db7-g7lpr 1/1 Running 0 4s
#这是因为当前的pod是由pod控制器创建的【即kubectl run +控制器】,
控制器会监控pod状况,一旦发现pod死亡,会立即重建
#此时如果想要删除pod,必须删除pod控制器
[root@master ~]# kubectl get deployment -n default
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 45h
#通过删除pod控制器的方式,来删除pod
[root@master ~]# kubectl delete deployment nginx -n default
deployment.apps "nginx" deleted
#发现pod被删除了
[root@master ~]# kubectl get pod -n default
No resources found in default namespace.配置操作
创建:
kubect create -f pod-nginx.yaml删除:
kubectl delete -f pod-nginx.yaml
4.3、Lable
Labe是kubernets系统中的一个重要的概念。它的作用就是在资源上添加标识,用来对它们进行区分和选择。
Labe的特点:
- 一个Labe会以key/value【键值对】的形式附加到各种对象上,如Node、Pod、Service等等
- 一个资源对象可以定义任意数量的Label,同一个Label也可以被添加任意数量的资源对象上去
- Label通常在资源对象定义时确定,当然也可以在对象创建后动态添加或者删除
可以通过Label实现资源的多维度分组,以便灵活、方便的进行资源分配、调度、配置、部署等管理工作
一些常用的Label示例如下:
版本标签:version:release、version:stable
环境标签:environment:dev、environment:test、environment:pro
架构标签:tire:frontend、tire:backend
标签定位完毕之后,还要考虑到标签的选择,这就要使用到Label Selector,即:
- Label用于给某些资源对象定义标识
- Label Selector用于查询和筛选拥有某些标签的资源对象
当前有两种Label Selector:
- 基于等式的Label Selector
- 基于集合的Label Selector
查看标签
#查看标签【--show-labels】
[root@master ~]# kubectl get pod -n test --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 3m57s run=nginx打标签
#为pod资源打标签
[root@master ~]# kubectl label pod nginx -n test vwesion=1.0
pod/nginx labeled
------------------------
[root@master ~]# kubectl get pod -n test --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 5m43s run=nginx,vwesion=1.0更新标签
#更新标签,加【--overwrite】
[root@master ~]# kubectl label pod nginx -n test version=1.0 --overwrite
-----------------------------------------------------
[root@master ~]# kubectl get pod -n test --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 9m3s run=nginx,version=1.0,vwesion=1.0筛选标签
#查看现在的pod
[root@master ~]# kubectl get pod -n test --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 19m run=nginx,version=1.0,vwesion=1.0
redis 1/1 Running 0 3m36s run=redis
#筛选标签【-l version=1.0】
[root@master ~]# kubectl get pod -l version=1.0 -n test --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 19m run=nginx,version=1.0,vwesion=1.0删除标签
#删除标签【标签- 例:vwesion-】
[root@master ~]# kubectl label pod nginx -n test vwesion-
pod/nginx unlabeled
#查看一下
[root@master ~]# kubectl get pod -n test --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 22m run=nginx,version=1.0
redis 1/1 Running 0 6m55s run=redis
4.4、deployment
在kubernets中,pod是最小的控制单元,但是kubernets很少直接控制pod,一般都是通过pod控制器来完成的。pod控制器用于pod的管理,确保pod资源符号预期的状态,当pod的资源出现故障时,会尝试进行重启或重建pod。
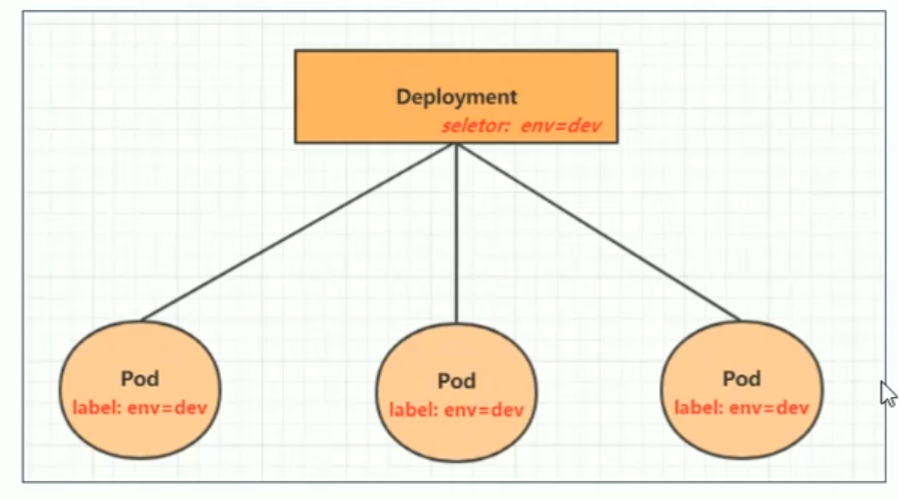
创建
#命令格式:kubectl create deployment 名称 [参数]
#--image 指定pod的镜像
#--port 指定端口
#--replicas 指定创建pod数量
#--namespace 指定namespace
[root@master ~]# kubectl create deployment redis --image=redis -n test
deployment.apps/redis created
4.4、Service
虽然每个Pod都会分配一个单独的Pod 的ip,然而却存在以下两个问题:
- Pod 的ip会随着pod的重建产生变化
- Pod的ip仅仅是集群内可见的虚拟IP,外部无法访问
这样对于访问这个服务带来了困难,因此,kubernetes设计了Service来解决这个问题。
Service可以看作是一组同类Pod对外的访问接口,借助Service,应用可以方便地实现服务发现和负载均衡 。
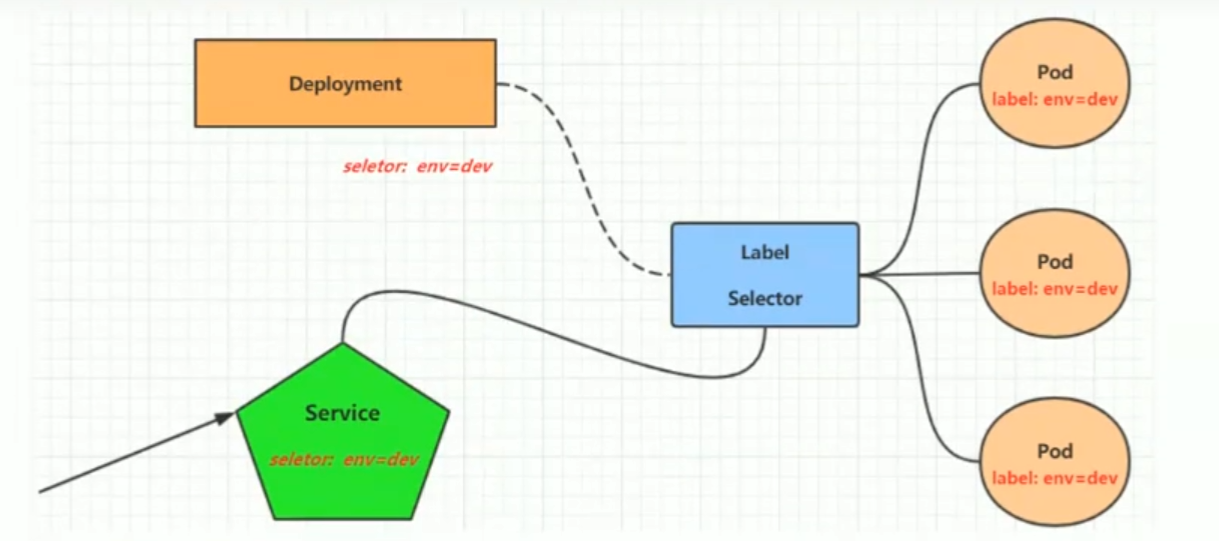
操作一:创建集群内部可访问的Service
#查看deploymnet
[root@master ~]# kubectl get deployment -n test
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 0/1 1 0 4s
redis 1/1 1 1 56m
#暴露service
【--name】指对service名称
【expose deploymnet 参数】暴露deployment指定service
【--type=ClusterIP】这里产生的是service的ip,在service生命周期中,这个地址不变
[root@master ~]# kubectl expose deployment nginx --name=svc-nginx1 --type=ClusterIP --port=80 --target-port=80 -n test
service/svc-nginx1 exposed
#查看service
[root@master ~]# kubectl get service -n test
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc-nginx1 ClusterIP 10.102.249.25 <none> 80/TCP 26s
操作二:创建集群外部可访问的Service
#上面创建的--type=ClusterPord是集群内部的访问端口
#如果需要集群外部访问,则需要将type类型改成--type=NodePort
[root@master ~]# kubectl expose deployment nginx --name=svc-nginx --type=NodePort --port=80 --target-port=80 -n test
service/svc-nginx exposed
#此时查看,就会发现出现了type为NodePort类型的service,而且有一对Port(80:30413/TCP)
[root@master ~]# kubectl get service -n test
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc-nginx NodePort 10.100.51.151 <none> 80:30413/TCP 12s
svc-nginx1 ClusterIP 10.102.249.25 <none> 80/TCP 10m
#即可用外部地址node2上的:192.168.80.12:30413进行访问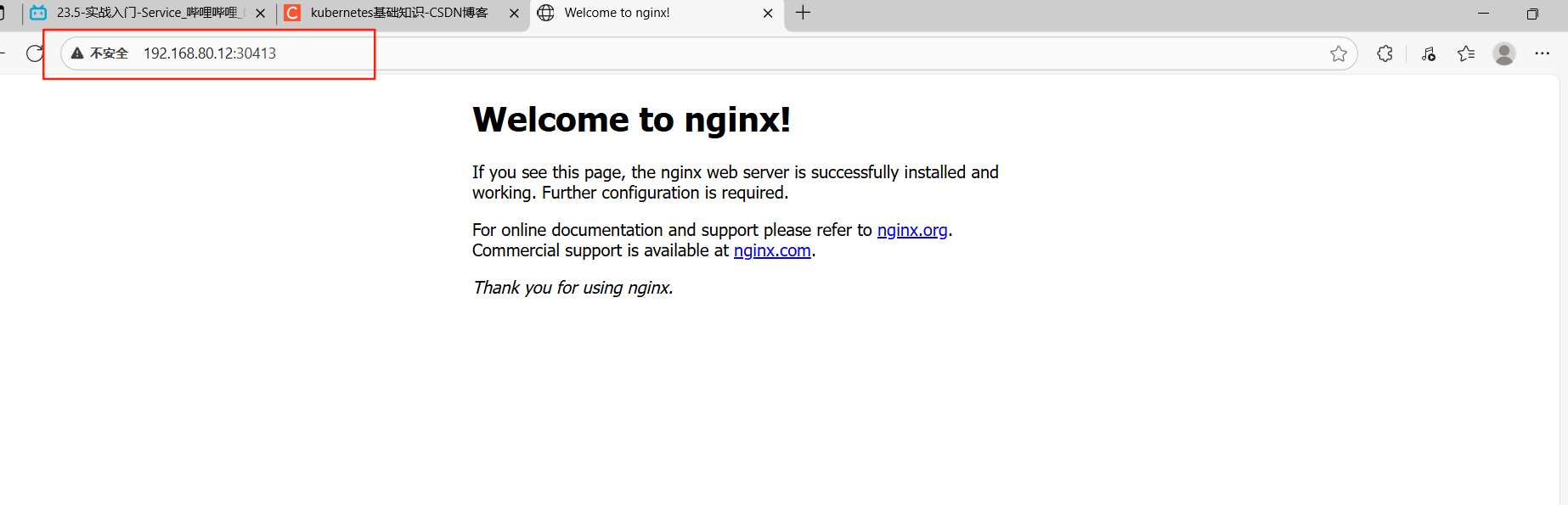
删除Service
[root@master ~]# kubectl delete service svc-nginx1 -n test
service "svc-nginx1" deleted作者:做个超努力的小奚&kervin24
个人博客站:http://www.kervin24.top
CSDN博客:https://blog.csdn.net/qq_52914969?type=blog




